

Key Takeaways
-
SEO crawling refers to how search engines find, retrieve, and render pages as a prerequisite for your site to rank.
-
By optimizing your internal links, sitemaps, and crawl budget, you can ensure search engines find and prioritize your most valuable content.
-
Technical issues such as server response, site architecture, and handling of hidden content have a direct bearing on how effectively crawlers can index your pages.
-
Google Search Console, server logs, and spider tools all help monitor and improve crawl performance for better SEO.
-
By solving typical roadblocks such as technical errors or slow page speeds, you optimize the experience for users and search engines alike.
-
Consistent auditing and continual optimization are the secret sauce for excellent crawlability that generates rankings and organic traffic.
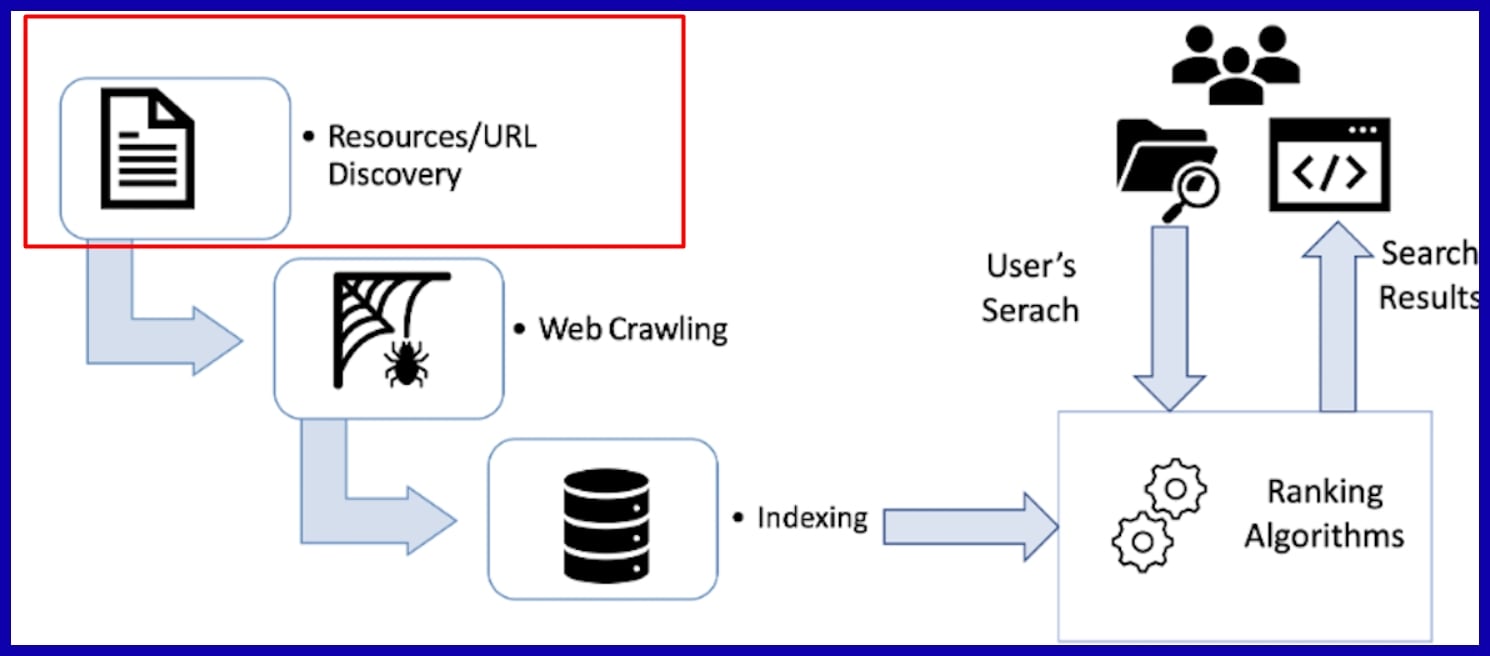
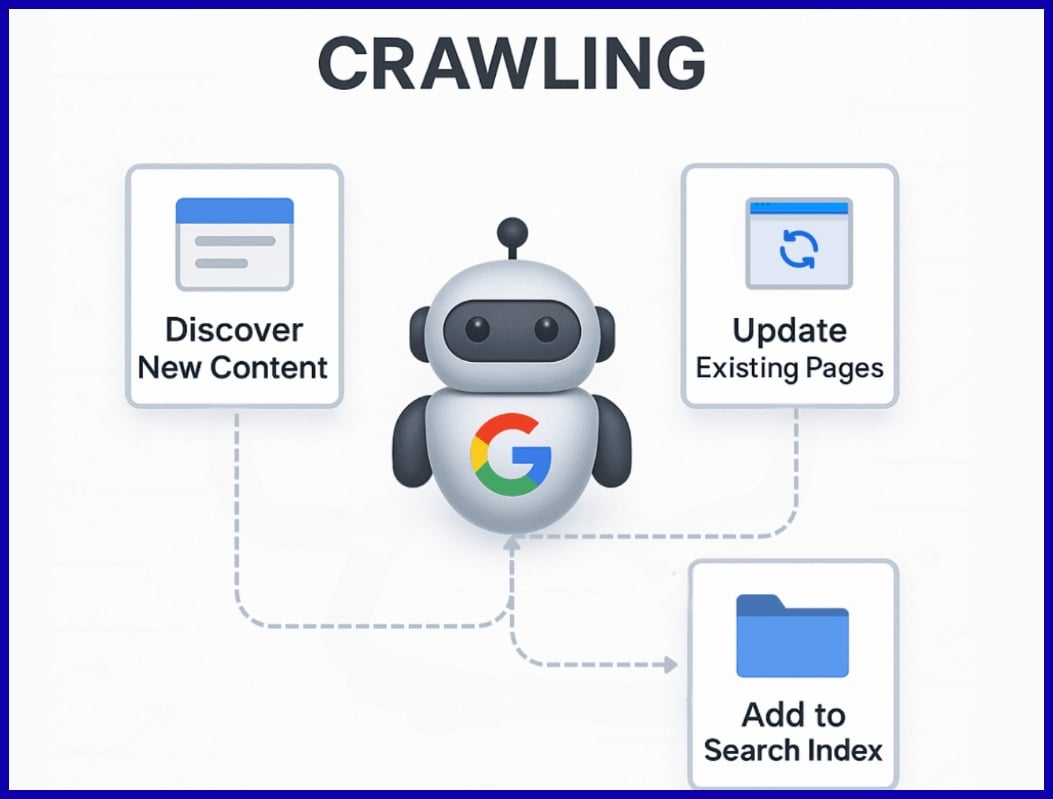
SEO crawling is a process where search engines systematically browse websites to gather and index information for ranking. Crawlers, sometimes referred to as spiders or bots, crawl site pages, links, and content to assist search engines in comprehending what each page is about.
Crawl efficiency ensures that important pages get indexed and appear in search results. For anyone seeking robust SEO results, crawlability is critical. The next parts explain how it all comes together.
Let’s get started.
What is SEO Crawling?
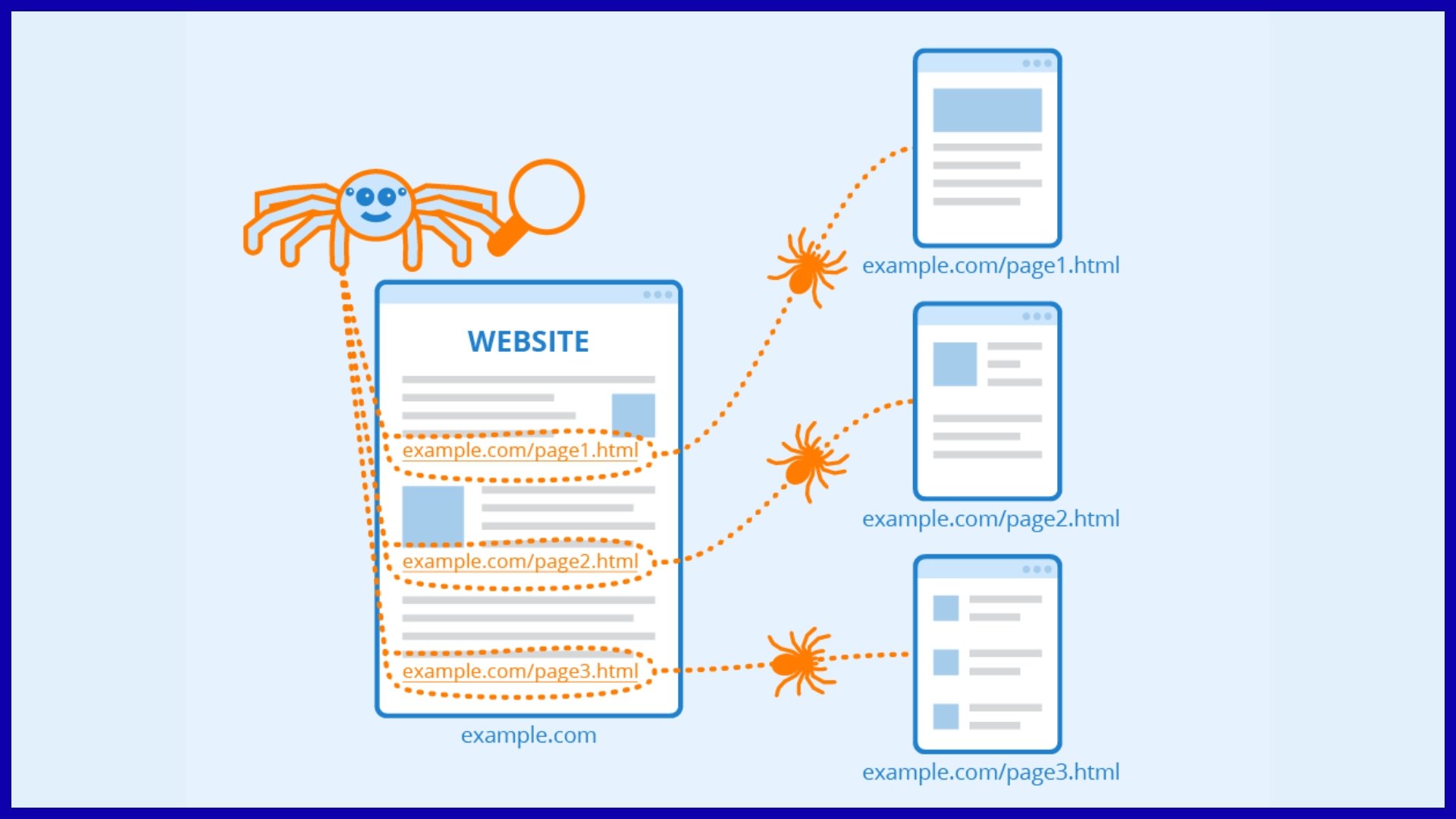
SEO crawling is the foundation of how search engines such as Google find, read, and index pages. Bots, referred to as crawlers or spiders, scour billions of URLs and follow links, studying content and constructing a searchable index.
Think of crawling as a librarian strolling through infinite library stacks, sampling new volumes, refreshing the old, and arranging them all just so for readers to discover. This repeats continuously. Websites are not frozen in time, and search engines need to repeatedly return to sites to discover new or changed content.
How often a site is crawled and how deep depends on a number of factors such as:
-
Authority
-
Site quality
-
Update cadence
-
Internal structure
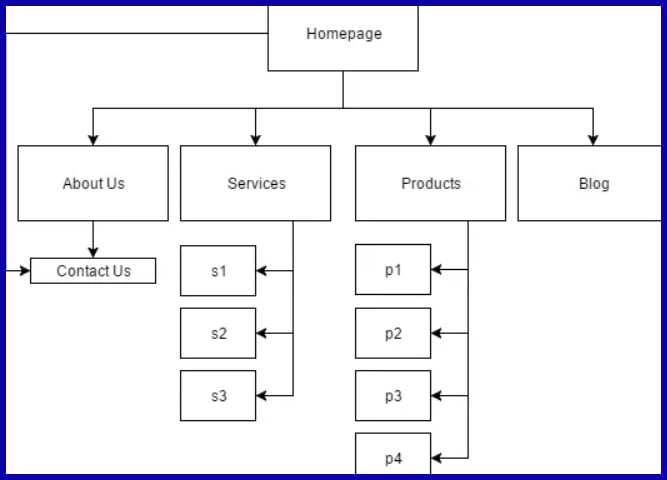
A transparent, rational site architecture enables search bots to easily navigate and index content, enhancing your probability for better rankings.
1. The Discovery
Discovery begins when crawlers arrive on a page and then pursue links to new or modified URLs. Internal links such as navigation menus or related-article blocks serve as signposts, guiding bots where to crawl next.
Sitemaps play a vital role too; they are like a guided tour, pointing search engines to important content you want indexed. Googlebot will usually look for a sitemap in your robots.txt or scan the HTML source for a sitemap reference first.
Search engines crawl in order of authority and relevance, so the most valuable, most frequently updated pages get priority. If key content is five clicks deep with no links to it, bots might not discover it.
2. The Fetching
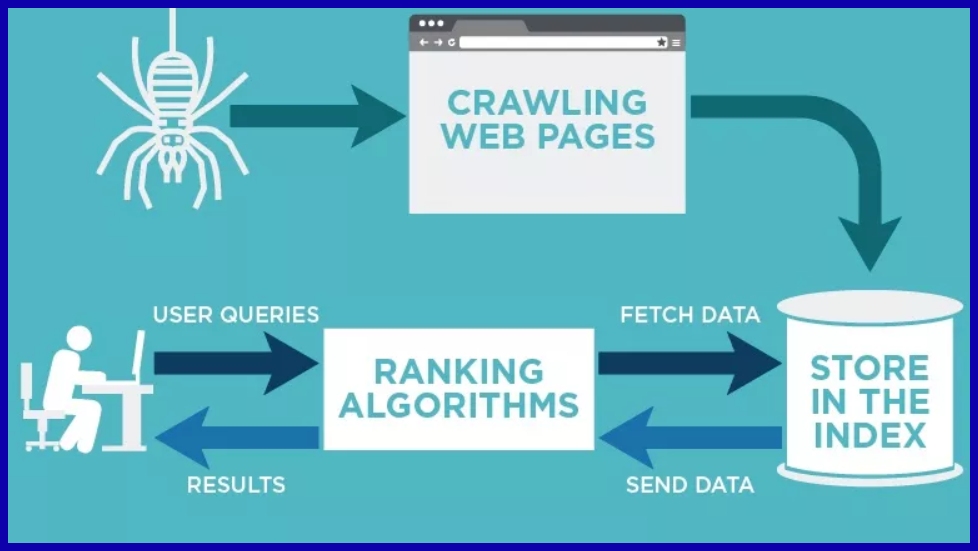
Once discovered, crawlers fetch HTTP requests to obtain the actual content of each page. Each time a bot requests a URL, the server returns the page content, including HTML, images, and scripts.
Quick and dependable server responses accelerate fetching, while slow servers or frequent errors, such as 404s, redirects, or blocked content, squander crawl budget and may prevent indexing entirely.
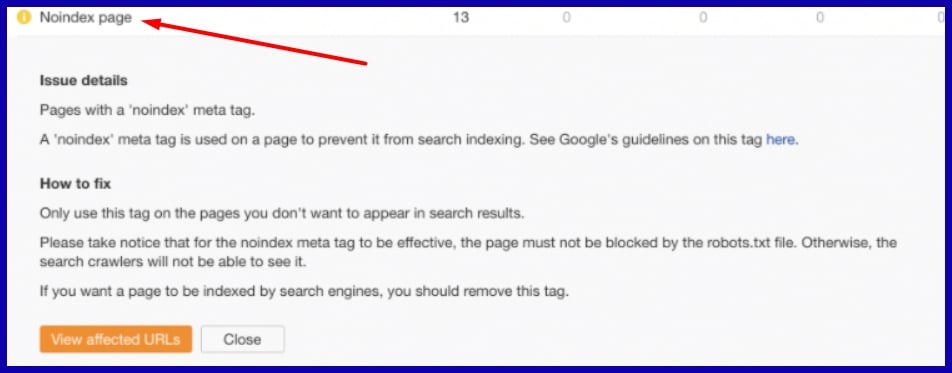
Typical crawl errors are URLs obstructed by robots.txt or noindexed, which stop search engines from accessing or listing crucial content.
3. The Rendering

Rendering is where crawlers make sense of the retrieved content, processing it to comprehend structure, context, and semantics. Modern sites tend to lean on JavaScript, which can make rendering more difficult and, at times, hide critical content from bots.
If your primary content loads only post script execution, there’s a risk that search engines won’t catch a glimpse. Making sure all of your valuable content is reachable at this point is critical.
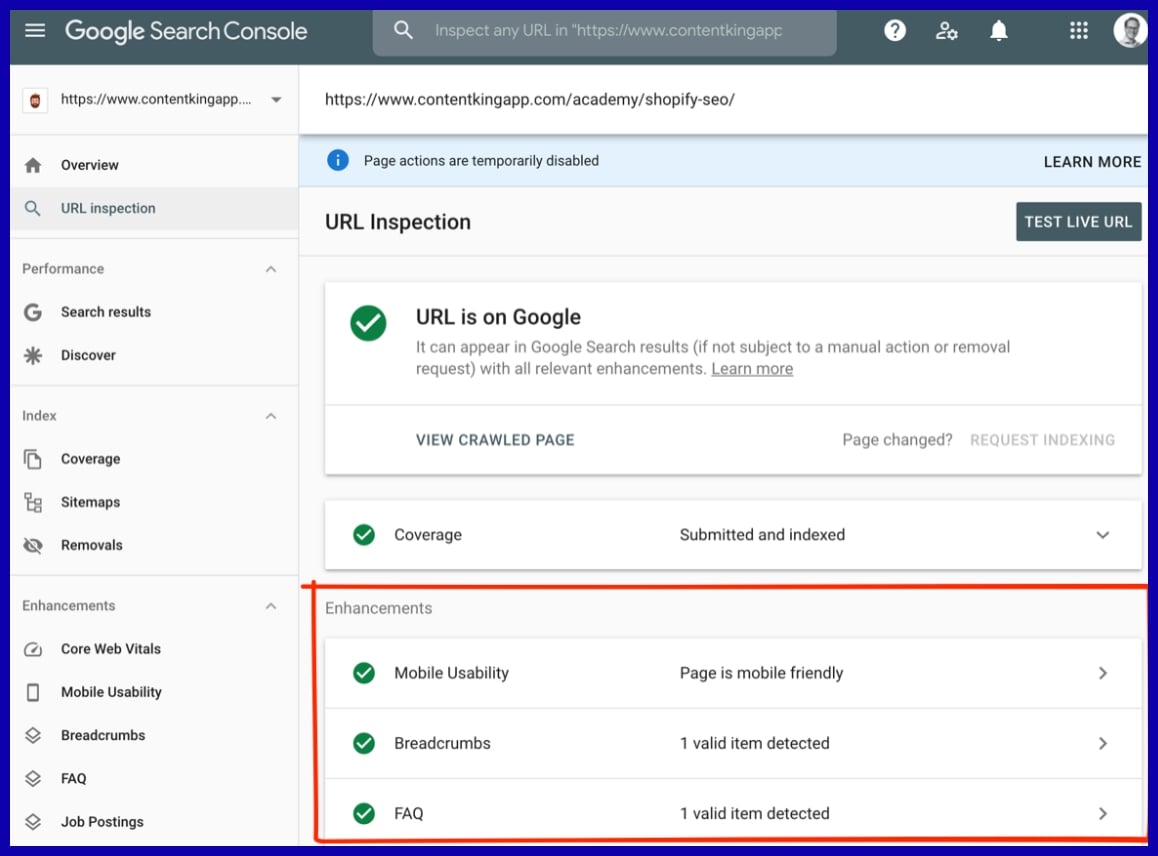
Google’s Search Console’s URL Inspection and Screaming Frog’s JS rendering mode are both useful tools to test and debug how bots see your pages.
4. The Budget
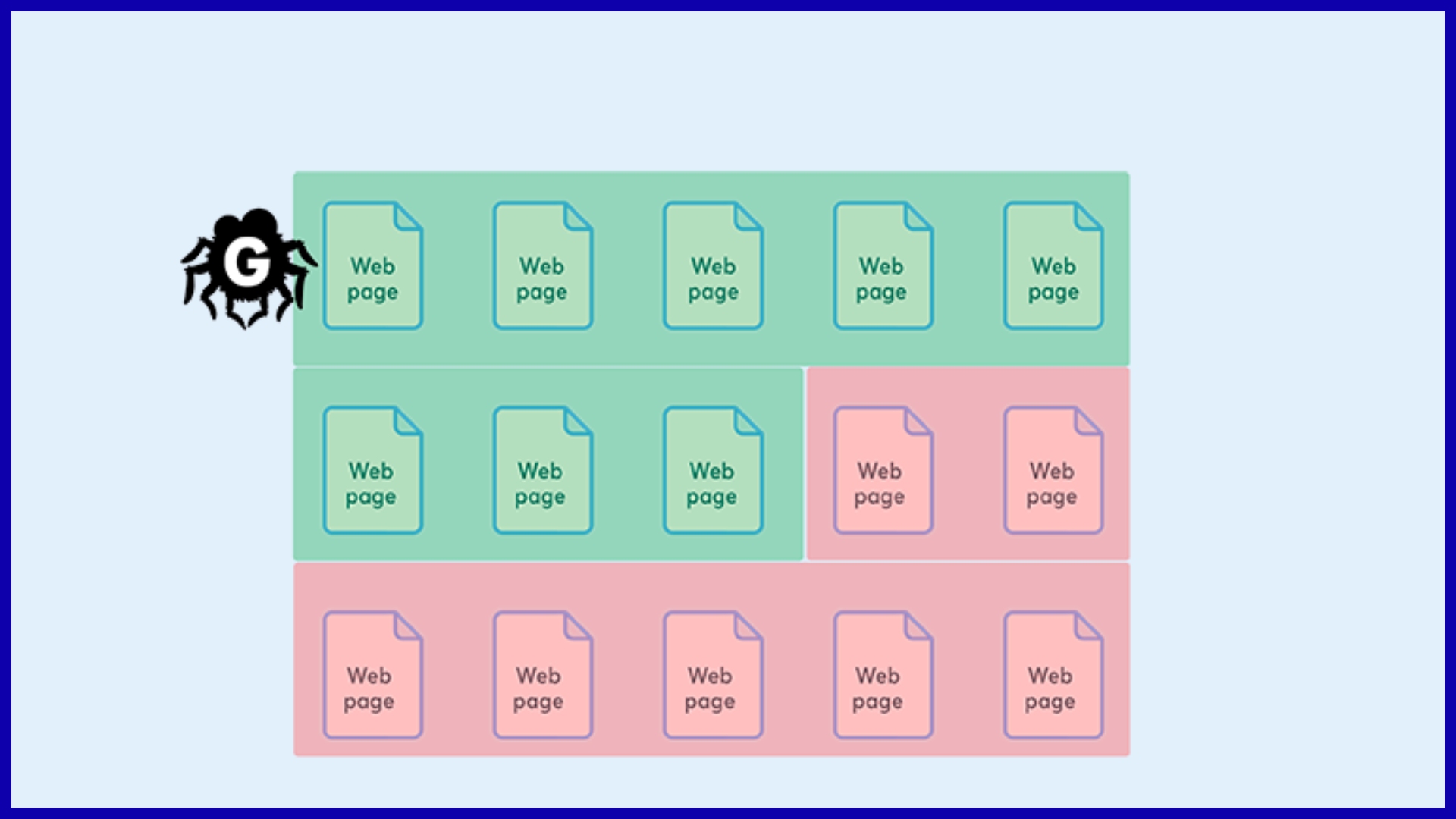
Crawl budget is how many pages a search engine crawls on your site in a given period of time. It’s affected by site size, authority, how often you update, and technical health.
Wasting crawl budget on low-value or broken pages means less important URLs get indexed. Keeping your site lean by pruning old, duplicate, or low-quality pages helps maximize the impact of each crawl.
Regular audits with tools like Google Search Console can bring problems to the surface and assist you in prioritizing repairs.
5. The Analogy

Picture your site as a giant library. Crawling is the librarian’s job: discovering new books, updating old ones, and placing everything in the right section.
Good crawling means every book (page) is discoverable, indexed, and convenient to searchers. If the librarian overlooks books stashed in back rooms or misfiles them, they won’t appear in the catalog, just as uncrawled or badly linked pages won’t show up in search results.
With robust internal linking, straightforward navigation, and a consistent site review, you can make sure your crawlers don’t miss a thing, bringing more relevant visitors to your site.
Why Crawling Matters
Why? Because search engines work by crawling, it matters significantly for website owners. This process is the basis for indexing and ranking in search engine results. Whether you operate a global e-commerce site or a niche blog, how you handle crawl efficacy affects your SEO results and, in turn, your bottom line.
Visibility
When a crawler visits your site, it scans and organizes your content so it can be indexed. Indexed pages are stored in huge databases that power search results. If a page isn’t crawled or indexed properly, it might never appear in Google—even if the content is amazing.
Common issues like duplicate pages, broken links, or crawl traps can hide your best content. That’s why tools like sitemaps (to point crawlers toward important URLs) and robots.txt files (to keep crawlers away from low-value pages like logins or duplicates) are so important.
Indexing
Crawling and indexing go hand in hand in any successful white label SEO strategy. Search engine crawlers first discover your pages, then evaluate whether they’re worth storing and ranking. Strong technical SEO—no broken links, clean site structure, and good internal linking—makes this process smooth.
For example, if you sell thousands of products online, crawlers need to index both your product and category pages. Regularly checking crawl stats in Google Search Console helps ensure your key pages are being seen and stay visible over time.
One way to check your indexed pages is “site:yourdomain.com”. Just go to Google and type “site:yourdomain.com” into the search bar. This will return the results Google has in its index for the site specified.
Look at this, for example:
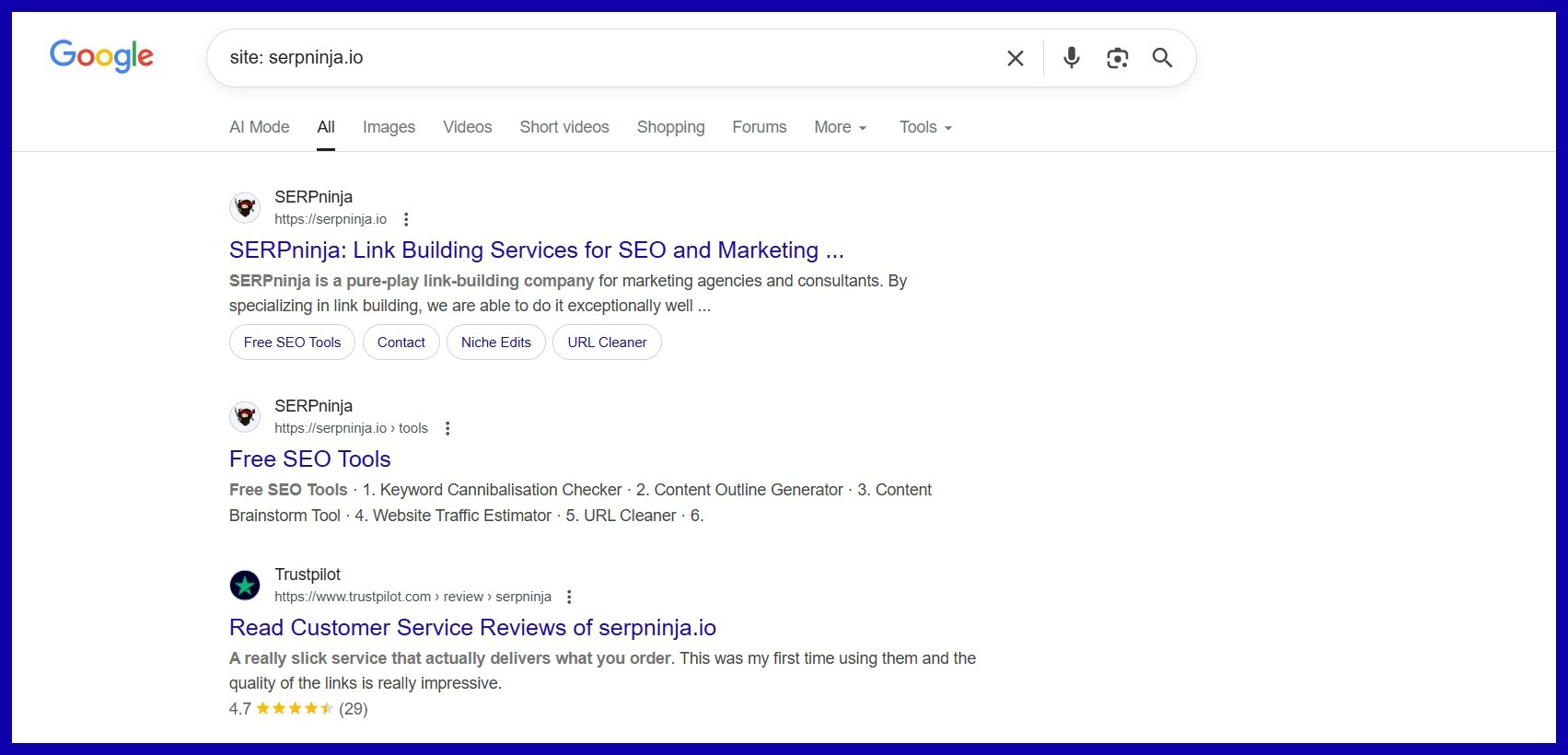
Ranking
Once crawled and indexed, your pages can compete for rankings.
Here’s where directing crawler behavior helps:
-
Robots.txt blocks crawlers from wasting time on duplicate or unimportant pages.
-
Sitemaps highlight the pages that matter most, like new blog posts or product launches.
-
Meta tags (noindex, nofollow) let you control what gets shown in search results.
Together, these tools guide crawlers toward your most valuable content, protect your crawl budget, and increase your chances of showing up higher in search.

How to Guide Crawlers
Guiding crawlers involves ensuring that your website’s most important content is discoverable, accessible, and indexable, while keeping certain pages, such as sensitive or irrelevant ones, out of their way. This process requires a mix of technical controls, like the robots meta tag, and planning to enhance crawl efficacy by using effective SEO tools.
Robots.txt
Robots.txt is your site’s front line. It informs search engines which pages or folders to keep out, controlling crawl behavior at the portal.
For example, blocking /admin/ or /cart/ prevents private or low-value content from being crawled.
Creating clear, effective robots.txt directives requires specifying user-agents, using “Disallow” for sensitive paths, and being careful not to accidentally block essential pages. If you accidentally block your “/blog/” folder, your content marketing could disappear from search results overnight.
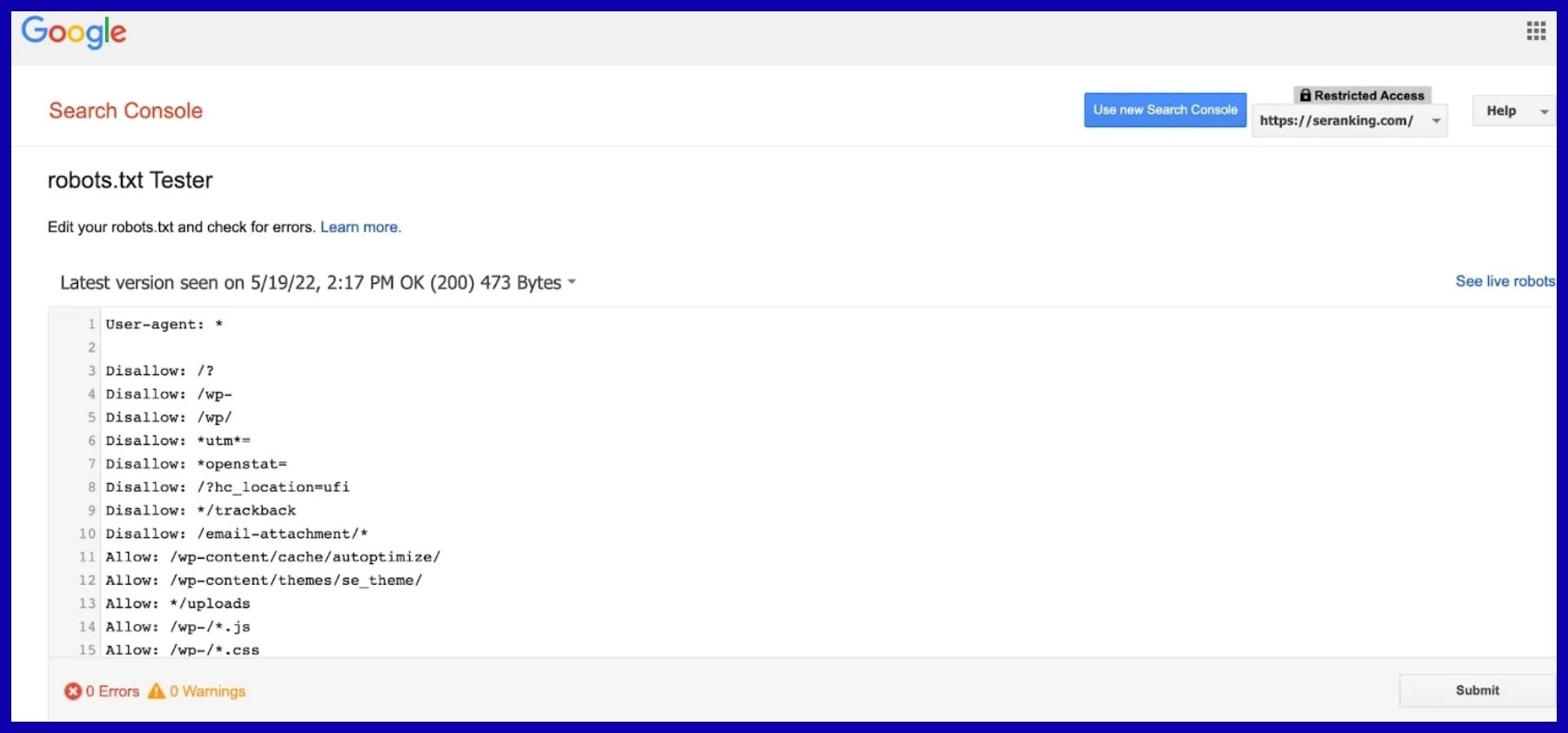
Keep robots.txt updated as your site evolves, and test changes with Google’s Robots.txt Tester to avoid typos or misconfigurations that could block entire sections by mistake.
Sitemaps
Sitemaps give search engines a shortcut to your priority pages. An XML sitemap is simply a list of URLs you want indexed, but it helps crawlers find new content or updates quicker, sometimes within an hour if everything’s tuned right.
For optimal impact, keep sitemaps up to date, only include canonical URLs, and don’t bloat them with parameter URLs or paginated duplicates. Submitting sitemaps through Google Search Console instead makes sure crawlers always have the freshest list.
It’s savvy to disallow login pages, filtered results, and anything “noindex”—otherwise, crawl budget is squandered on dead ends. When a new page isn’t getting indexed, usually it’s not in the sitemap or isn’t linked anywhere internally.
Meta Directives
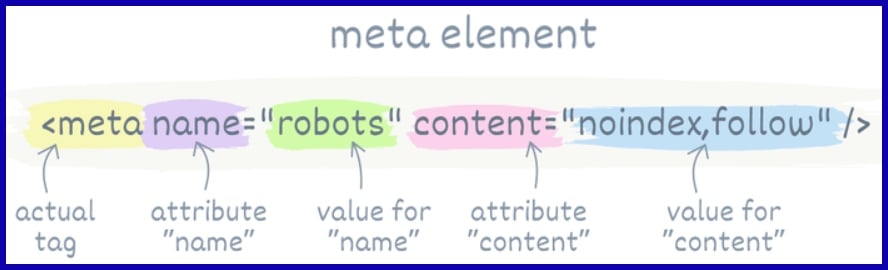
Meta directives allow you to shape indexing at the page level. Noindex” is your friend for those checkout or thank-you pages you don’t want in search results, but still want users to reach.
Well-written meta descriptions and titles increase crawl efficiency and assist search engines in determining the purpose of the page, aiding ranking. Canonical tags are crucial for managing duplicate content by directing crawlers to the favored variant when duplicates are present.
Without canonicals, search engines may waste resources crawling duplicates, which poisons your SEO. Keep using these tags on product variations, language versions, or tracking URLs.
Common Crawling Obstacles
There are a few things that can stall or derail crawling. Weak internal linking creates orphan pages, hidden from both bots and users. Redirect chains or loops, particularly broken 301 redirects, can confuse crawlers and waste crawl budget.
Slow page load speed is another silent killer. Bots will give up on you if your site loads too slowly. Invisible, or ‘hidden’, content such as text that loads after scripts or behind logins will not be indexed.
Server errors (5xx) block all access, so routine audits with tools like Screaming Frog or Google Search Console assist in quickly identifying and resolving problems. Regardless of what you do, always test redirects and canonical tags, and make navigation easy for both bots and humans.
Conclusion
SEO crawling is never really a ‘background’ task—it’s the lifeblood that powers your visibility and viability on the SERPs. Knowing how crawlers work, why they matter, and what can trip them up gives you actual leverage. From examining crawl stats and robots.txt tune-ups to advanced technical dives, each step contributes to a streamlined, easily indexed website. Crawling may seem technical, but the impact is direct: clear site structure, fewer indexing headaches, and steady organic growth.
If you’ve optimized your crawl, it means the search engines discover your best content without getting too lost. Tools like SERPninja make it easier to stay on top of audits and technical fixes, so you can focus on building content that converts.
Frequently Asked Questions
What is SEO crawling?
SEO crawling refers to how search engine bots crawl website pages, enhancing crawl efficacy and helping search engines process and index your content for better rankings in search engine results.
Why is crawling important for SEO?
Crawling matters because it ensures search engines work effectively to discover your web pages and index them, allowing your content to appear in search engine results.
How can I help search engine crawlers access my site?
Make sure your site is structured well, use a sitemap, and keep robots.txt open to important pages to enhance the crawl efficacy of your content.
What are the common obstacles that block crawling?
Typical issues, such as broken links, suboptimal site structure, or slow-loading pages, can hinder the crawl efficacy of search engine bots from indexing your content.
How do I analyze crawl data?
Utilize instruments such as GSC to examine crawling reports and improve crawl efficacy. Check for pages that are not indexed or have crawl errors.
What should I do if my site is not being crawled?
Examine your robots.txt to ensure your site is accessible, and create a sitemap to assist search engine bots while fixing broken links for improved crawl efficacy.
Can crawl budget affect my site’s SEO?
Yes, if a website has a large number of web pages, search engines allocate a crawl budget. By controlling site structure and eliminating duplication, search engine bots can focus on key pages.








