

Key Takeaways
-
Top-notch AI training data is to machine learning what books are to a student.
-
These diverse, structured, and accurate datasets are needed to build reliable, fair, and high-performing AI models across industries globally.
-
Data preparation — annotation, cleaning, verification — is a never-ending cycle that directly influences AI’s precision and trustworthiness.
-
Mitigating issues such as data scarcity, noise, and drift requires continual monitoring, external collaboration, and the use of synthetic data to augment real-world samples.
-
Ethical data practices like safeguarding privacy, obtaining consent, and documenting provenance build trust and ensure compliance in AI initiatives.
-
If you’re developing AI-based solutions, you need to put in the time and effort to acquire, train, and ethically manage training data to produce results you can trust.
AI training data refers to the datasets used to teach artificial intelligence models how to recognize patterns, make predictions, and perform tasks.
Top-notch training data is the lifeblood of crafting trustworthy AI across industries from healthcare to finance. The precision, variety, and applicability of these datasets directly impact how effectively an AI model trains and executes.
By investigating the composition and significance of AI training data, we can better understand why it counts in real-world machine learning.
What is AI Training Data?

AI training data is the foundation of any machine learning project. It’s the raw material—text, images, audio, and more—that nourishes algorithms and fuels learning. In a sense, training data is both the workbook and the test sheet for AI models, leading them to learn what patterns, relationships, and results.
Enterprises can spend as much as 80% of their project time simply sourcing, cleaning, and preparing this data, illustrating its fundamental importance in producing trustworthy results. The quality and diversity of this data is crucial, not only for technical precision but for making sure models behave fairly and ethically. Similarly to how a student’s knowledge reflects the textbooks and experience they learn from, an AI model’s performance mirrors the richness and scope of its training data.
1. The Foundation

Effective AI training datasets are built from a mix of core elements: labeled examples, structured formats, and a broad sampling from the target domain. Text, audio, and image prompts all contribute depending on the assignment. For example, a voice assistant depends on tagged voice data, whereas an autonomous vehicle utilizes millions of tagged images.
Diversity in datasets counts. Without it, models risk bias, making bad decisions in the real world. Structured data—imagine neat spreadsheets or labeled photos—guides algorithms through the noise. The training dataset directly influences the AI’s learning trajectory and effectiveness; hence, it is the cornerstone in model training.
2. The Process
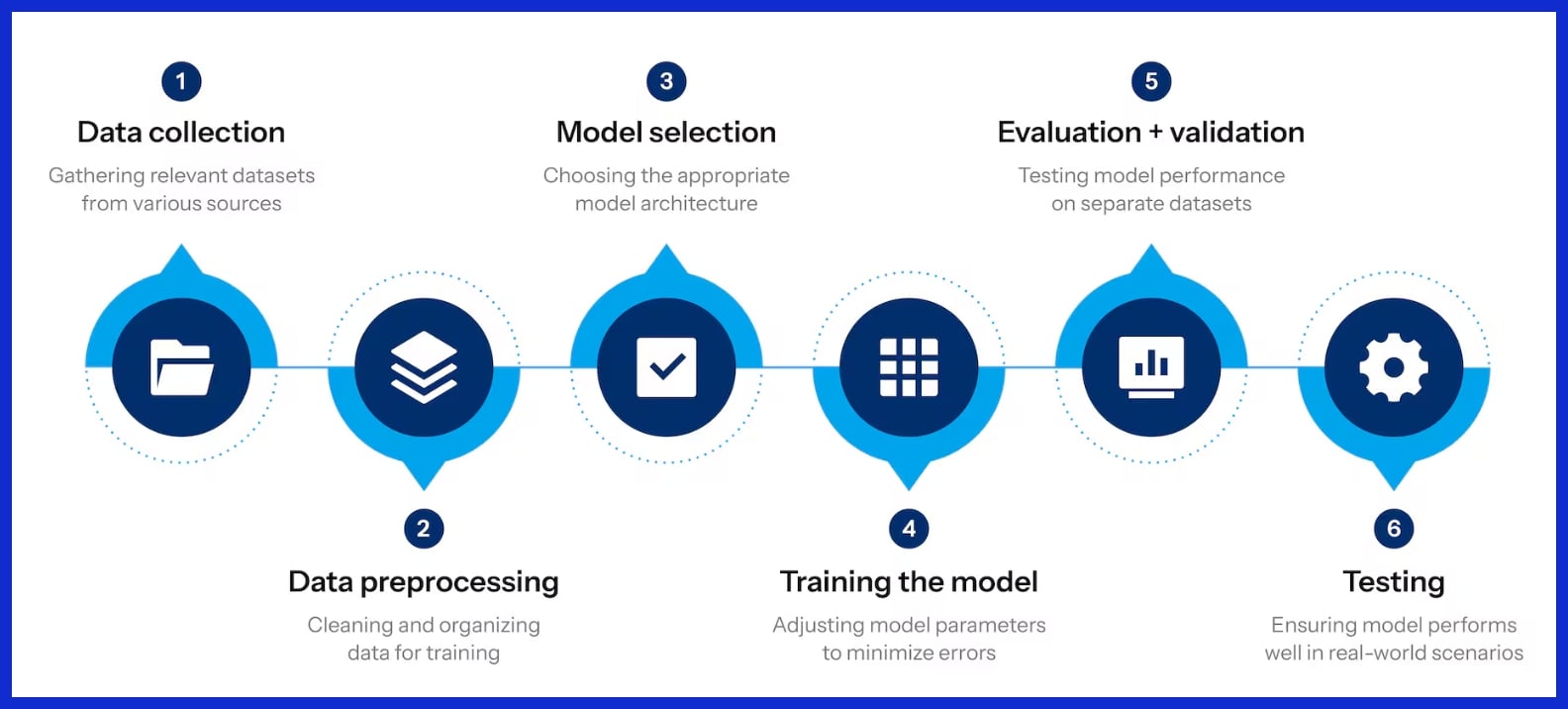
First, data is gathered from databases, sensors, or even crowdsourcing platforms that assign labeling to massive distributed work forces. Next is preprocessing, which involves cleaning, normalizing, and occasionally augmenting the data to make sure it’s consistent and usable. This step is crucial because bad data makes for bad models.
The training is iterative. The model trains, then tests, then iterates. Online learning systems update their datasets too, improving accuracy as they receive new data. These cycles help prevent overfitting, which is too specific, and underfitting, which is too generic, ensuring the model remains flexible and resilient.
3. The Goal
The goal is to allow the AI model to generalize from examples such that it can make accurate predictions or classifications on unseen data. Success hinges on measures such as accuracy, recall, and precision, which are hallmarks of quality datasets.
With robust training data, AI services from language translators to fraud detectors can provide reliable, practical performance. Cross validation, utilizing several data partitions, confirms the model generalizes beyond its training setting. It’s the right data that enables AI to fulfill its potential.
4. The Analogy
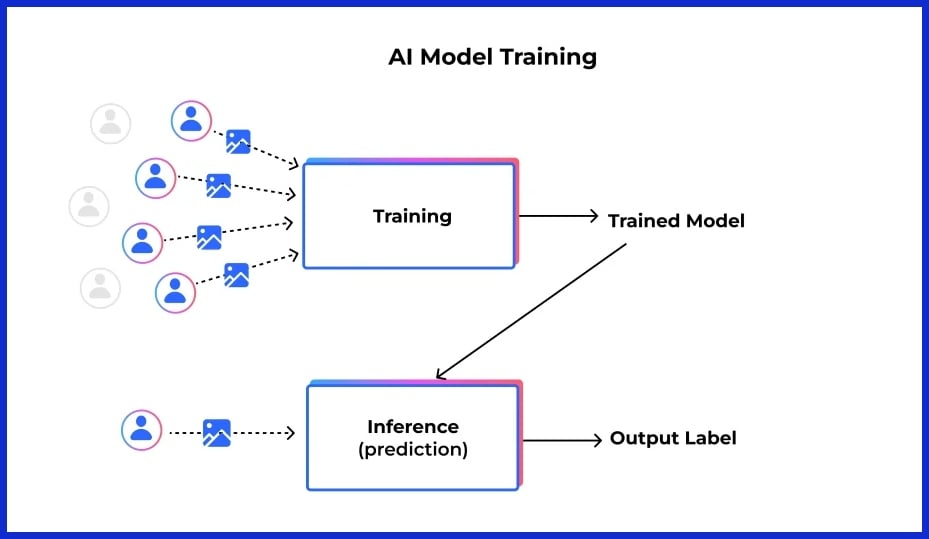
Think of training an AI model as teaching a student with textbooks, exercises, and quizzes. If the textbooks are out of date or too specialized, the student stumbles on life’s exams. Real-world examples such as handwriting or accents underscore the value of rich, quality datasets.
Think of a chef training with a single ingredient — their abilities are constrained. In AI, rich and well-annotated data is the entire pantry. Without it, models cannot grow the nuance or flexibility required by real-world applications.
Why Quality Data Matters
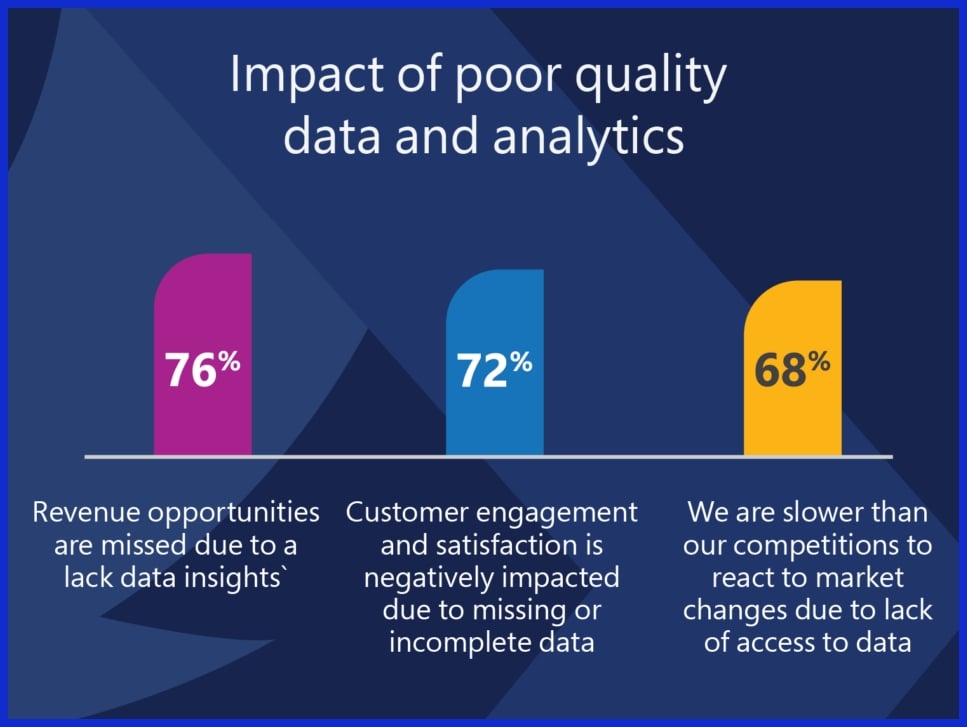
Quality data is at the core of the success of any AI project. The fit, veracity, and dependability of your training data inform every prediction, suggestion, and result an AI system provides. In practice, this is the difference between an AI that enhances and one that just complicates.
When we say quality here, we mean more than pristine spreadsheets—it is about continuous watchfulness, neutral sources, and data that adapts as the world changes. The consequences of cutting corners can be harsh: misleading outputs, systemic bias, and costly wrong turns.
Accuracy
Precise training data provides AI models the focus they require to generate trustworthy forecasts. When the data is high quality, the model can identify patterns, detect subtle differences, and refrain from hallucinating. This truth connects directly to model evaluation metrics, including precision, recall, F1 score, and others, since bad data pulls these metrics down, regardless of how advanced the algorithm.
Keeping this information accurate requires regular audits, cross-checking with reliable sources, and utilizing automated data validation technologies. For instance, in language models, ambiguous or mislabeled texts lead the AI to misinterpret phrases or produce nonsensical responses.
Flawed data not only drives down accuracy, but it can result in mortifying public errors or even damage the reputation of companies making AI-powered decisions.
Reliability
Reliable data, in the context of AI, refers to information that consistently behaves as anticipated across different situations and periods. For AI models, this equates to consistent and reliable performance on novel or unseen examples. Steady data streams are essential because they keep your model from ‘pop and fizzle’ in moments of stress or when moving to a new setting.
Validation through random sampling and cross-checking helps ensure reliability. Without them, models might slide into overfitting or underfitting and fail to generalize. One of my favorite mistakes is to put together data from sources with changing standards or missing entries, creating volatile forecasts.
|
Pitfall |
Description |
|---|---|
|
Inconsistent data formatting |
Different units, date formats, or conventions |
|
Data drift |
Changes in source data over time |
|
Incomplete records |
Missing key fields or values |
|
Lack of version control |
Overwriting or losing track of data changes |
|
Source bias |
Over-reliance on a single or narrow data provider |
Fairness

Fairness in AI training data means that the model’s predictions don’t discriminate against any group. Biased datasets can perpetuate stereotypes or make decisions that exclude. This is not only an ethical concern, but it’s also a business risk.
Diverse data are crucial to fairness, providing the model a more complete view of the world. When training data includes diverse scenarios, languages, and demographics, AI models are less prone to outputting biased results.
-
Use demographic analysis to spot underrepresented groups
-
Apply bias detection algorithms to flag problematic patterns
-
Regularly review and update datasets for inclusivity
-
Engage domain experts to audit for hidden biases
The Data Quality Dilemma
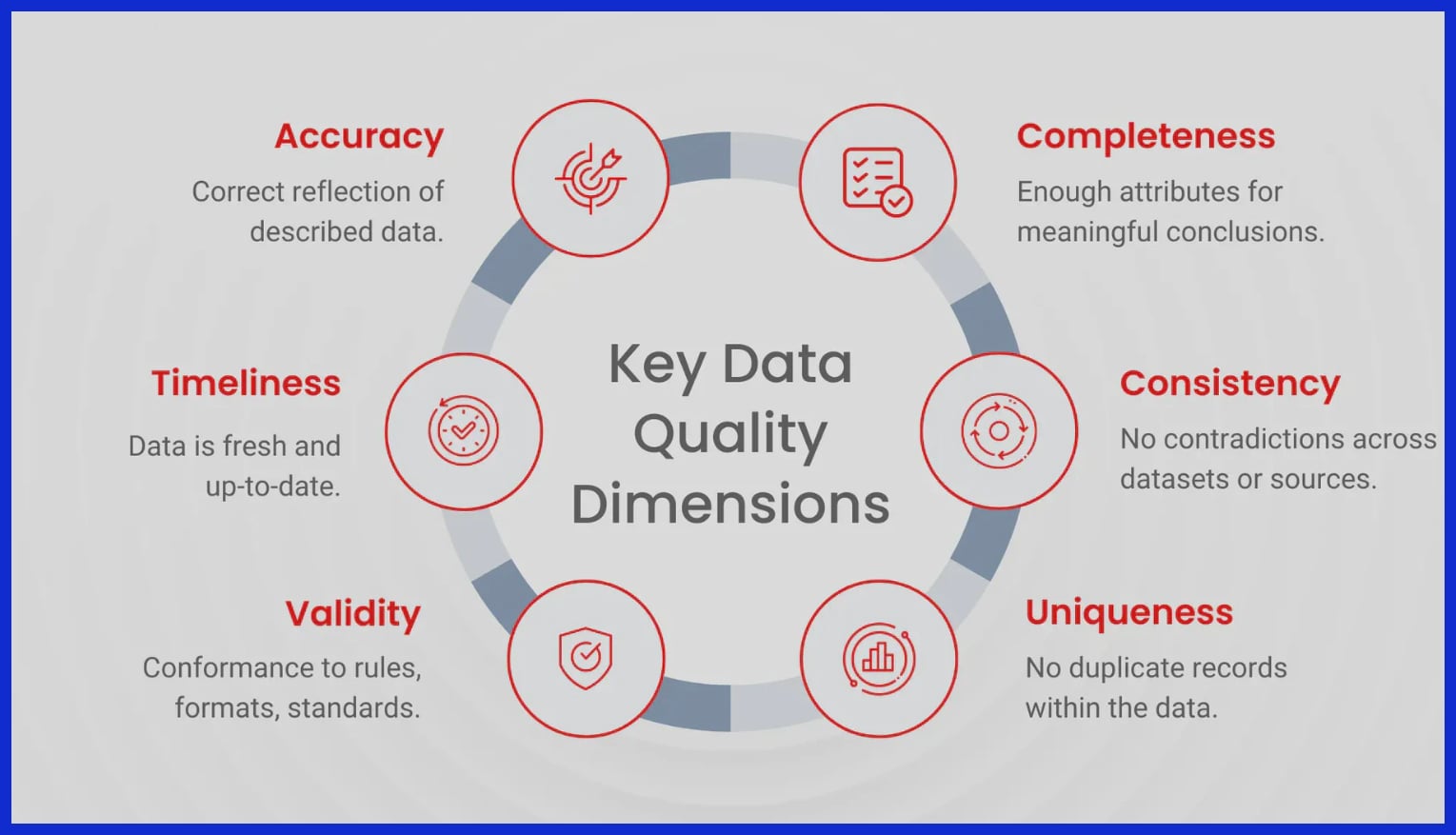
AI’s potency is closely linked to the quality ai training data it ingests. The dilemma surrounding data quality remains an open research problem. As AI adoption proliferates, enterprise leaders and AI specialists are discovering fissures in their data infrastructure. Structuring a quality dataset is critical to the model training process, yet this task is often easier said than done.
Even with emerging paradigms such as coupling deep learning with statistical outlier detection, solutions frequently miss the mark. The tension between data quality and quantity is palpable. Insufficient data raises concerns about bias and underfitting, while excessive noise can hinder your model’s ability to detect the signal.
The “Goldilocks Zone” of data—just enough, just right—is becoming increasingly challenging to achieve, especially with the EU AI Act and state laws raising the standards for privacy, quality, and data provenance.
Data Scarcity
Access to great datasets is the number-one roadblock for AI projects. When data is insufficient, models go hungry for the patterns they must learn, resulting in incorrect or prejudiced responses. This problem is especially pronounced in sectors such as healthcare or finance, where privacy regulations limit the ability to share data and anonymization reduces its worth.
Bad data, in fact, killed 85% of AI initiatives recently according to reports and the same has been found by watchdogs such as the EU. Beating scarcity can demand ingenuity. Synthetic data generation, data augmentation, and transfer learning supplement real world data.
Cross-industry partnerships and open data initiatives fill the gaps, particularly when organizations come together to share non-sensitive datasets. Public repos, crowdsourcing, internal logs, and other potential sources of extra training data each have their own quality and privacy dilemmas.
Cross-industry and research-community collaboration is important too, not only for combining data but for creating common standards and best practices that serve us all.
Data Noise
Data noise is irrelevant, misleading, or erroneous information within a dataset. It muddies the learning process, resulting in models that are less trustworthy and more inaccurate. Noisy data slips in via sensor errors, human input errors, or ambiguous tags.
The impact is clear: dirty data can derail entire projects if left unchecked. Mitigating noise begins with intense data scrubbing, which includes deduplication, error correction, and format normalization. Automated anomaly detection methods, such as statistical models, can identify outliers and need human review.
Feature selection and dimensionality reduction assist in separating the signal from the noise. Periodic audits of data pipelines, continuous validation, and transparent documentation practices are essential for maintaining noise levels to a minimum.
|
Source of Noise |
Example |
|---|---|
|
Measurement errors |
Faulty sensor readings |
|
Human input mistakes |
Typo in manual data entry |
|
Inconsistent labeling |
Different annotators, same data |
|
Data integration errors |
Mismatched formats |
Data Drift
Data drift happens when the statistical characteristics of the training data shift over time. It’s particularly pertinent in fast changing domains, such as fraud detection or e-commerce, where customer behavior or market conditions can shift rapidly. If a model is trained on yesterday’s patterns, it will miss today’s patterns, sabotaging business results.
Its results can be as benign as mild performance dips or as severe as model crashing. Regularly monitoring data distributions, employing drift detection algorithms, and periodically retraining your models are all effective strategies to stay ahead.
Having automated alerts for sudden data changes can help teams react quickly. Continuous monitoring isn’t a must have. Regulations now require organizations to demonstrate their models are trained on representative, current, and high-quality data, and vigilance is essential to any enterprise AI strategy.
Sourcing Your Datasets

AI models are only as good as the data behind them. Sourcing your training datasets is a strategic decision that shapes your accuracy, fairness, and long-term value of your project. Whether your data is coming from within your company, outside vendors, or synthetically generated, there are trade-offs to each approach.
Take into account the legal, ethical, and technical implications for strong, compliant, and impactful AI implementations.
Common methods for sourcing AI training datasets include:
-
Downloading from public data repositories
-
Purchasing datasets from commercial providers
-
Gathering exclusive information through first-party channels or inside systems
-
Aggregating sensor or IoT device data
-
Generating synthetic data using algorithms
-
Collaborating with research or industry partners for shared datasets
Public Sources
Tapping free datasets from trusted public sources can get AI model-building projects off to a quick start, particularly in the early project phases. Popular dataset platforms such as Kaggle, UCI Machine Learning Repository, and Google Dataset Search feature millions of datasets spanning Vision, NLP, and tabular data.
Other reliable sources are Open Data portals from governments and international organizations. Public datasets save you the effort and expense of collecting data by providing a ready-made base for prototyping or benchmarking models.
However, pitfalls lurk in the varying quality of the datasets and in the absence of key metadata or context. Our public datasets have a language bias, leaning heavily toward English and the languages of Western Europe. Licensing is another headache.
Error rates in license categorization can be over 50%, and omission rates may exceed 70%, creating legal uncertainty. As with any data, check the dataset origin, licensing terms, and whether warranties or indemnities are given to protect against infringement claims. This transparency and attribution matter for compliance and to give credit where it’s due.
Private Collection
Gathering proprietary data allows customized AI applications to solve distinct business problems. Internal sources, such as customer data, transaction logs, or device-generated data from IoT networks, produce high relevance and competitive advantage.
In regulated industries, private collection enables more control of data provenance and compliance. For best results, establish clear data collection protocols: define consent requirements, document data provenance, and ensure robust security.
Ethical matters come first. Data privacy laws such as GDPR or CCPA are global, so mask sensitive fields and honor user permissions. A great proprietary dataset makes your AI model more difficult for competitors to copy, reinforcing your market advantage.
The infrastructure, time, and governance investment is non-trivial.
Synthetic Generation
Synthetic data is generated through algorithms and not statistically collected from real-world occurrences. It plugs holes in current datasets, mitigates bias, or mimics low-frequency scenarios. For instance, computer vision squads create synthetic images to teach autonomous cars how to handle bizarre road scenarios.
This technique offers major benefits. It scales quickly, reduces privacy risks, and can balance underrepresented classes or languages. Examples include:
-
Healthcare—simulate rare diseases for diagnostic AI model testing.
-
Finance—generate transactional records for fraud detection.
-
Manufacturing—model defect scenarios in quality control.
-
Retail—create synthetic customer journeys for recommendation systems.
Quality control is key. Badly produced synthetic data can add artifacts or unrealistic patterns, compromising model truthfulness. Always audit and validate synthetic samples against real-world benchmarks.
Conclusion
AI training data lies at the heart of every great machine learning system. Quality, relevance, and ethical sourcing influence not only how well a model performs but also whether it can be trusted in the real world. There are many paths to constructing and acquiring datasets, but the human element—thoughtful selection, annotation, and ethical validation—means everything. Navigating the tradeoff between scale and quality takes practice and continual work. As AI advances, so do standards for openness and equity. Teams that make these values front and center will experience better outcomes and cultivate more trust. Trustworthy, useful AI always begins with the right data and the right mindset directing every action—an approach teams like SERPninja quietly champion in their work.
Frequently Asked Questions
What is AI training data?
Quality AI training data can be text, images, audio, or video. Top-notch datasets enable AI models to learn to make accurate predictions or decisions.
Why is high-quality training data important for AI?
High-quality ai training data ensures AI systems learn the right patterns and do not make mistakes. Reliable training datasets mean better performance, more trustworthy results, and less bias risk for AI use.
How do organizations source AI training datasets?
They acquire quality AI training data from public repositories, licensed providers, or by developing proprietary collections. High-quality datasets sourced from trusted sources enhance the precision and trustworthiness of AI model training.
What role do humans play in AI training data?
Humans actually label and review data, contributing to the generation of quality AI training data that mirrors real-life scenarios, minimizes mistakes, and enhances AI model training responses.
What are the main data quality challenges in AI?
Data quality challenges encompass incomplete, inaccurate, or biased data, which can hinder the training model’s effectiveness. Routine sampling and varied data sources help ensure quality AI training data, mitigating these issues.
How does data ethics affect AI training data?
Ethical considerations in AI model training guarantee that quality AI training data is gathered, stored, and utilized responsibly, fostering trust through privacy and consent.
Can low-quality training data harm AI outcomes?
Indeed, using quality AI training data is crucial, as poor data can lead AI models to err or be biased, resulting in inconsistent output and skepticism toward AI-enabled tools.








